Category: Architecture
-

It’s Time to Play the Music
Ever felt your design review was less constructive critique and more… relentless heckling from a balcony? A couple of years ago, when I worked at Quint I wrote an article together with Rob Swinkels for the magazine called Informatie. It was based on the ideas of Mark de Bruin who stated that as an architect…
-
From Blueprint to CTO
Stolen from https://static.vecteezy.com/ From Blueprint to CTO Martijn Veldkamp "Strategic Technology Leader | Customer’s Virtual CTO | Salesforce Expert |…
-
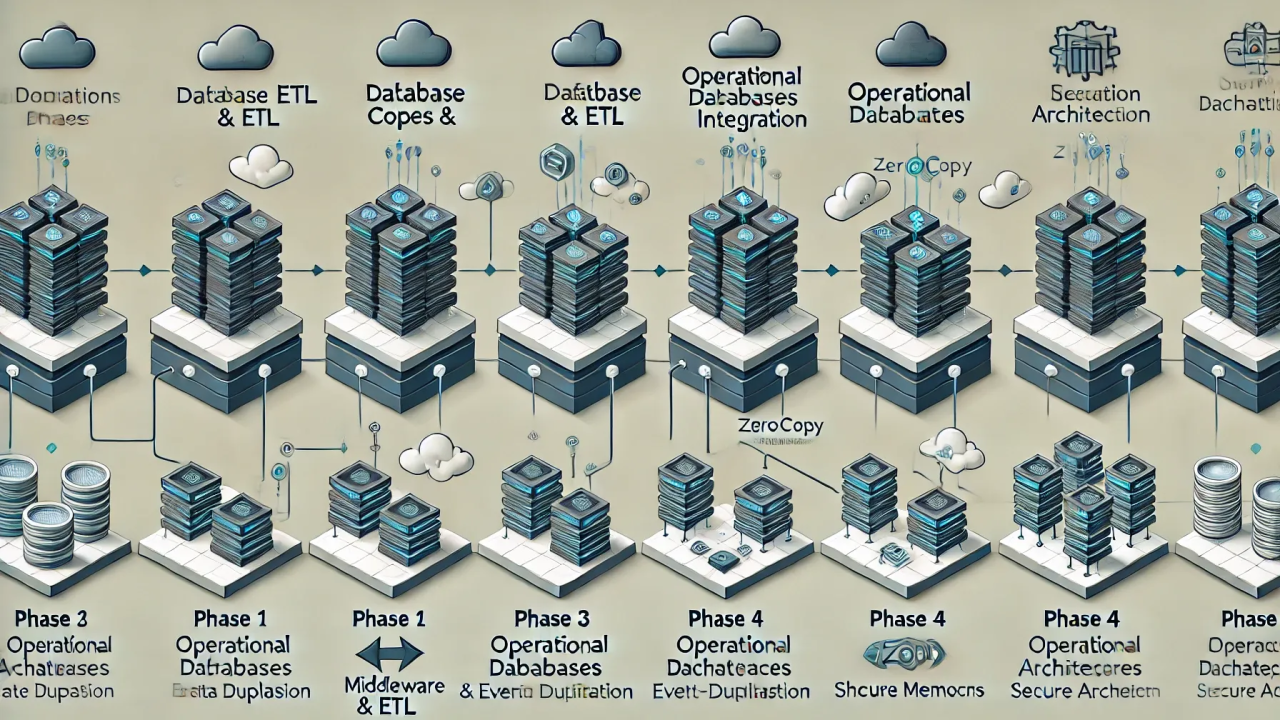
The Evolution of Data Integration
In today’s interconnected applications landscape, we rely on data shared across multiple systems and services. Throughout my career as an architect, integration strategies have evolved from basic ETL database copies to monolithic middleware, operational databases, API-driven microservices, and now ZeroCopy patterns. As I’m almost a year older again I look back at all the stuff…
-

Architecture is Like a Game of Cluedo
Really? Designing an architecture is as fun as a game of Cluedo? I know, they seem worlds apart. One is a classic murder mystery board game, and the other is a structured approach to solving complex technical problems. However, when you squint your eyes a bit and look a bit cross-eyed, the process of uncovering…
-
Gravitational Lensing in Digital Transformation
I love when I am walking the dog and different words or concepts mesh together and give me a new way to think about my experiences as an architect and consultant. With digital transformation, organizations are traversing through a cosmic landscape where familiar landmarks seem to shift and/or warp under the influence of all these…
-
Complexity? It is everywhere!
All of us Architects have experience with our different customers and their complex and bulky application landscapes. And the numerous challenges that they cause. We are not allowed to change or update the MiddleWare because it is so critical for our day to day operations Usual Suspects The Usual Suspects https://www.imdb.com/title/tt0114814/ Next to high maintenance…
-
Delivery is like a Relay Run
As promised in my earlier blogs. I am writing a blog a month and I write about Architecture, Governance and Changing the Process or the Implementation and last month was about Technical debt. This month it is about going live successfully. Why? The relay run that the Dutch team lost due to a faulty handover…
-

Simplify Add Lightness Martijn Veldkamp
This famous quote is from Colin Chapman. It was his philosophy, somewhere in 1950 way before ‘minimalism’ became fashionable. Least number of parts By tradition, Lotus uses the least number of parts needed in its products. Yet, they are impeccably engineered, retain their lightness and work dependably. This is a great analogy and one we…
-

“Simplify, then add lightness”
“Simplify, then add lightness” This famous quote is from Colin Chapman. It was his philosophy, somewhere in 1950 way before ‘minimalism’ became fashionable.…
-
Software as an Onion (SaaO)
Software is like an onion. Your team’s code is one “layer” in this onion. There are layers below you (which you rely on), and layers above you (which rely on…